
开云「中国内陆」官方网站 更高效、更智能、更环保
你的位置:开云「中国内陆」官方网站 更高效、更智能、更环保 > 新闻资讯 >
发布日期:2026-01-23 08:12 点击次数:123

梦晨 发自 凹非寺
量子位 | 公众号 QbitAI智谱AI上市后,再发新恶果。
开源轻量级大谈话模子GLM-4.7-Flash,径直替代前代GLM-4.5-Flash,API免费绽开调用。

这是一个30B总参数、仅3B激活参数的搀杂内行(MoE)架构模子,官方给它的定位是“土产货编程与智能体助手”。
在SWE-bench Verified代码建筑测试中,GLM-4.7-Flash拿下59.2分,“东说念主类临了的考验”等评测中也显赫超过同范围的Qwen3-30B和GPT-OSS-20B。
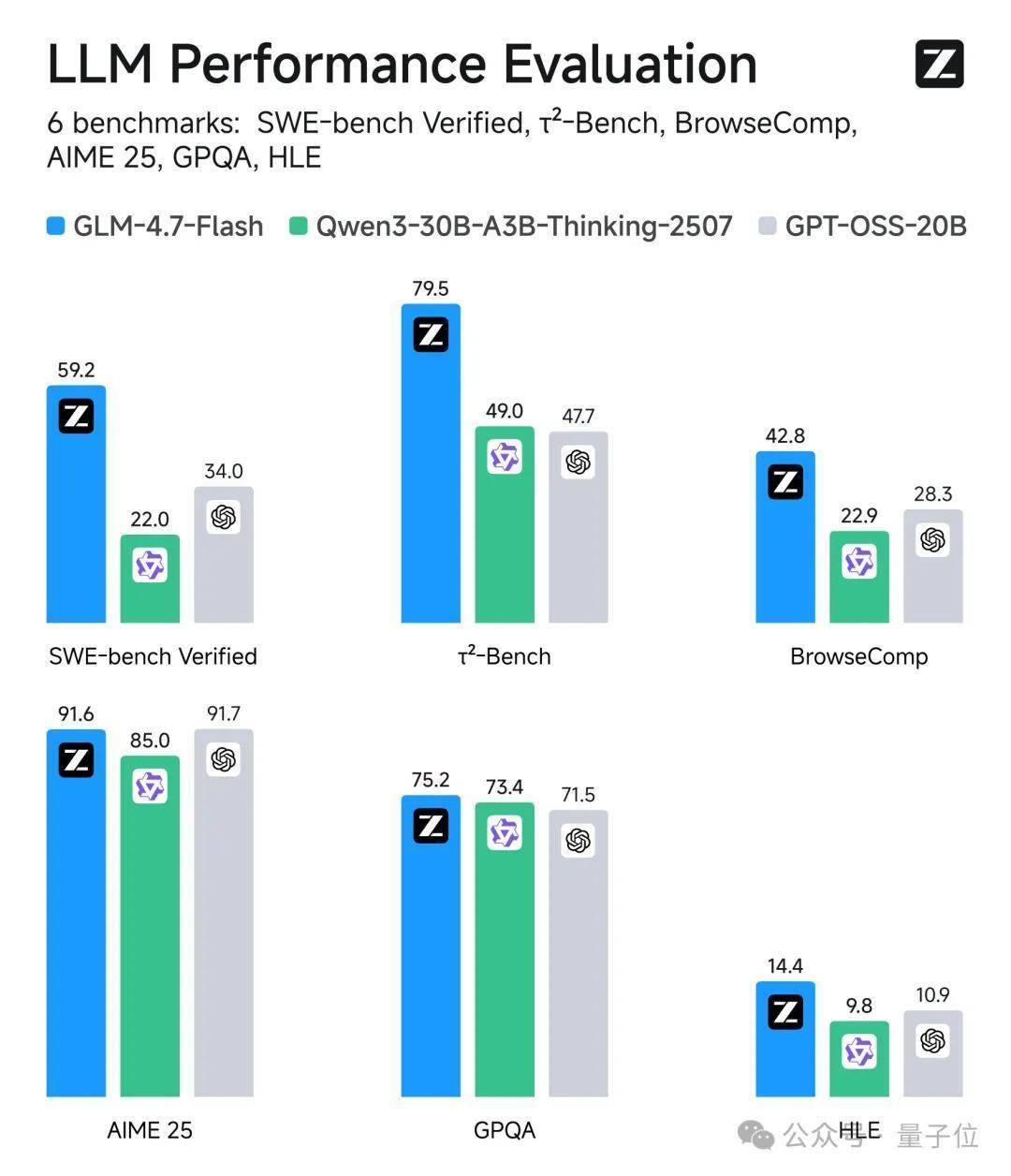
动作客岁12月发布的旗舰模子GLM-4.7的轻量化版块,GLM-4.7-Flash采纳了GLM-4系列在编码和推理上的中枢才智,同期针对着力作念了脱落优化。
除了编程,官方还推选将这个模子用于创意写稿、翻译、长高下文任务,以至脚色上演场景。
30B参数只激活3B,MLA架构初次上线GLM-4.7-Flash沿用了该系列的”搀杂念念考模子”的蓄意。
总参数目300亿,但本体推理时仅激活约30亿参数,使模子在保合手才智的同期大幅裁减预计支拨。
高下文窗口守旧到200K,既不错云表API调用,也守旧土产货部署。
现在官方还莫得给出本事证据,更多细节还要从建设文献我方挖掘。
有开导者凝视到一个蹙迫细节:GLM团队此次初次采纳了MLA(Multi-head Latent Attention)架构。这一架构此前由DeepSeek-v2领先使用并考证有用,如今智谱也跟进了。
从具体结构来看,GLM-4.7-Flash的深度与GLM-4.5 Air和Qwen3-30B-A3B接近,但内行数目有所不同——它采纳64个内行而非128个,激活时只调用5个(算上分享内行)。
现在发布不到12小时,HuggingFace、vLLM等主流平台就提供了day0守旧。
官方也在第一时候提供了对华为昇腾NPU的守旧。
土产货部署方面,经开导者实测在32GB长入内存、M5芯片的苹果条记本上能跑到43 token/s的速率。
官方API平台上基础版GLM-4.7-Flash弥漫免费(限1个并发),高速版GLM-4.7-FlashX价钱也极端白菜。
对比同类模子,在高下文长度守旧和输出token价钱上有上风,但现在蔓延和微辞量还有待优化。
HuggingFace:
https://huggingface.co/zai-org/GLM-4.7-Flash参考邻接:
[1]https://x.com/Zai_org/status/2013261304060866758Powered by 开云「中国内陆」官方网站 更高效、更智能、更环保 @2013-2022 RSS地图 HTML地图